在本章中,你将学习如何使用DreamFactory的API限制和日志功能来分配和监视对受限制API的访问。
日志记录
无论您是调试API工作流还是符合法规要求,日志记录都将在流程中发挥关键作用。在本节中,我们将回顾各种与配置和管理您的DreamFactory平台日志和通过DreamFactory的弹性堆栈集成管理的日志相关的最佳实践。
介绍DreamFactory平台日志
DreamFactory开发人员和管理员经常需要使用信息和错误消息来调试平台行为。此记录行为可以在您的.env文件或服务器环境变量。如果你打开.env你会在文件的顶部发现以下与日志相关的配置参数:
APP_DEBUG:当设置为时真正的,如果抛出异常,将返回调试跟踪。虽然在开发阶段很有用,但您无疑希望将其设置为假在生产万博max手机网页登录中。APP_LOG:默认情况下,DreamFactory将把日志条目写入一个名为dreamfactory.log中发现的存储/日志.这被称为单文件模式。您可以将DreamFactory配置为将日志条目分解为日常文件,例如dreamfactory - 2019 - 02 - 14. -日志通过设置APP_LOG来每天.但是请记住,默认情况下只维护5天的日志文件。您可以通过将所需的天数分配给APP_LOG_MAX_FILES.或者,您可以通过设置将日志条目发送到操作系统syslogAPP_LOG来syslog,或到操作系统错误日志使用errorlog.APP_LOG_LEVEL:该参数决定日志的敏感程度,可设置为调试,信息,请注意,警告,错误,至关重要的,警报,紧急.当此参数设置为时,DreamFactory可能非常健谈调试,信息,或请注意,因此在生产环境中使用这些设置时要谨慎。万博max手机网页登录此外,请记住这些设置是有层次的,这意味着如果您设置APP_LOG_LEVEL来警告例如,然后是所有警告,错误,至关重要的,警报,紧急消息将被记录。
下面是发送到日志的典型输出示例:
[2019-02-14 22:35:45] local。调试: API event handled: mysql._table.{table_name}.get.pre_process [2019-02-14 22:35:45] local.DEBUG: API event handled: mysql._table.employees.get.pre_process [2019-02-14 22:35:45] local.DEBUG: API event handled: mysql._table.{table_name}.get.post_process [2019-02-14 22:35:45] local.DEBUG: API event handled: mysql._table.employees.get.post_process [2019-02-14 22:35:45] local.DEBUG: Service event handled: mysql._table.{table_name}.get [2019-02-14 22:35:45] local.DEBUG: Logged message on [mysql._table.{table_name}.get] event. [2019-02-14 22:35:45] local.DEBUG: Service event handled: mysql._table.{table_name}.get [2019-02-14 22:35:45] local.DEBUG: Service event handled: mysql._table.employees.get [2019-02-14 22:35:45] local.INFO: [RESPONSE] {"Status Code":200,"Content-Type":null} [2019-02-14 22:35:45] local.INFO: [RESPONSE] {"Status Code":200,"Content-Type":"application/json"}Logstash
DreamFactory的黄金版通过Logstash连接器提供了弹性堆栈(Elasticsearch, Logstash, Kibana)支持。这个连接器可以很容易地与ELK堆栈的其余部分(Elasticsearch, Logstash, Kibana)进行接口Elastic.io或者连接到其他分析和监控源,如开源Grafana.
提示
如果你是Logstash的新手,正在寻找一个简单而便宜的方法开始,我们建议跟随优秀的数字海洋教程标题 如何在Ubuntu 18.04上安装Elasticsearch、Logstash和Kibana.要启用Logstash连接器,您将像配置任何其他服务一样开始。导航到服务,然后创建,然后在服务类型选择框选择Log > Logstash.然后,添加名称、标签和描述,就像配置其他服务一样:
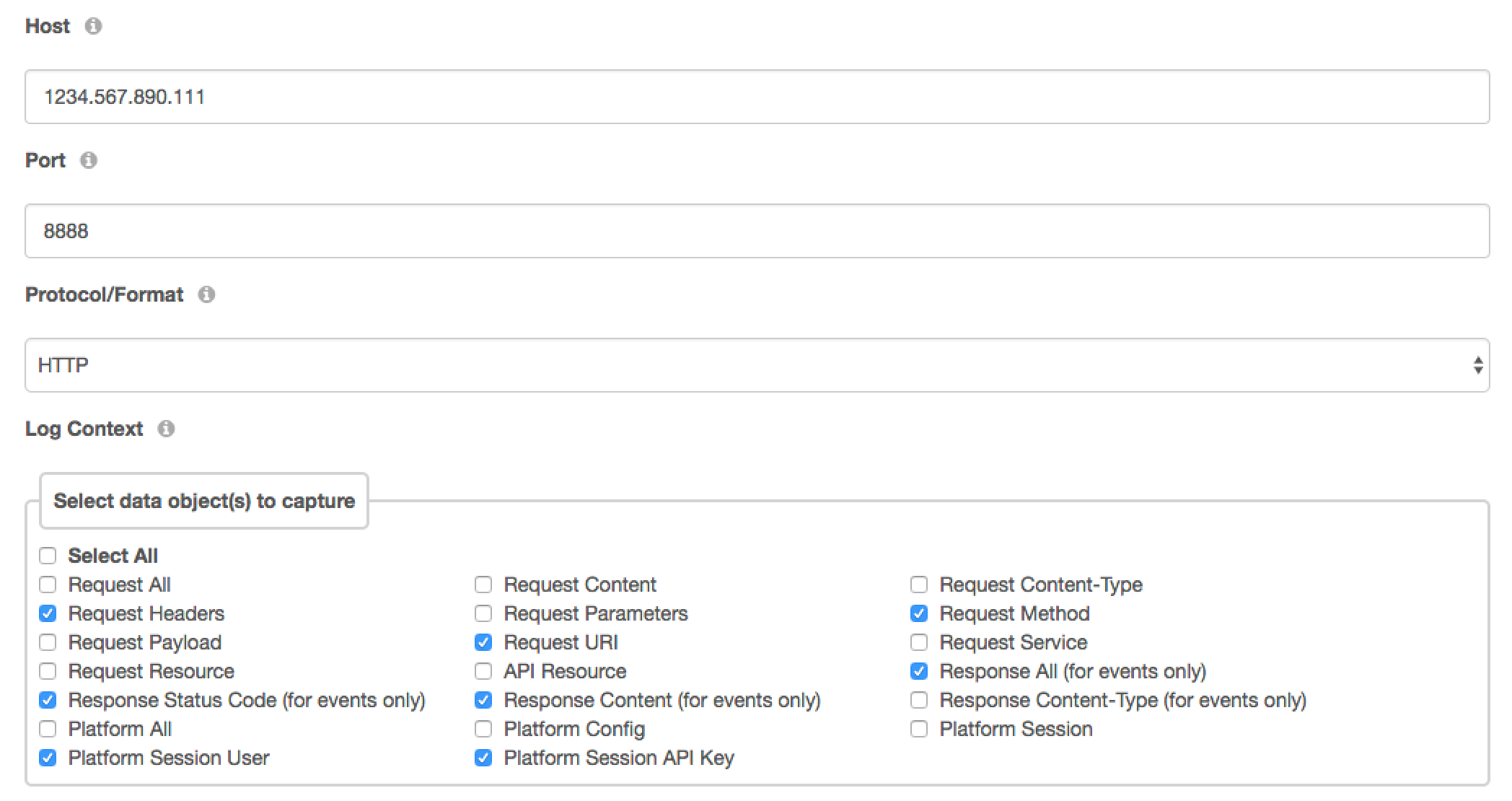
接下来,导航到服务创建页面顶部的“Config”选项卡。在接下来的两个屏幕截图中,您可以看到需要选择的字段和选项。在第一个截图中,您将添加主机。在这种情况下,我在本地托管Logstash连接器,在我的DreamFactory实例上。其他选项是港口而且协议/格式.该端口对应于运行Logstash守护进程的端口。的协议/格式字段应该设置为与你的Logstash服务被配置为接受输入的协议/格式匹配:
- gef (UDP): gef (GrayLog扩展格式)被创建为syslog格式化的优化替代方案。了解更多在这里.
- HTTP:如果您的Logstash服务配置为侦听HTTP协议,则选择此选项。DreamFactory将以JSON格式将数据发送到Logstash。
- TCP:如果您的Logstash服务配置为侦听TCP协议,则选择此选项。DreamFactory将以JSON格式将数据发送到Logstash。
- UDP:如果您的Logstash服务配置为侦听UDP协议,则选择此选项。DreamFactory将以JSON格式将数据发送到Logstash。
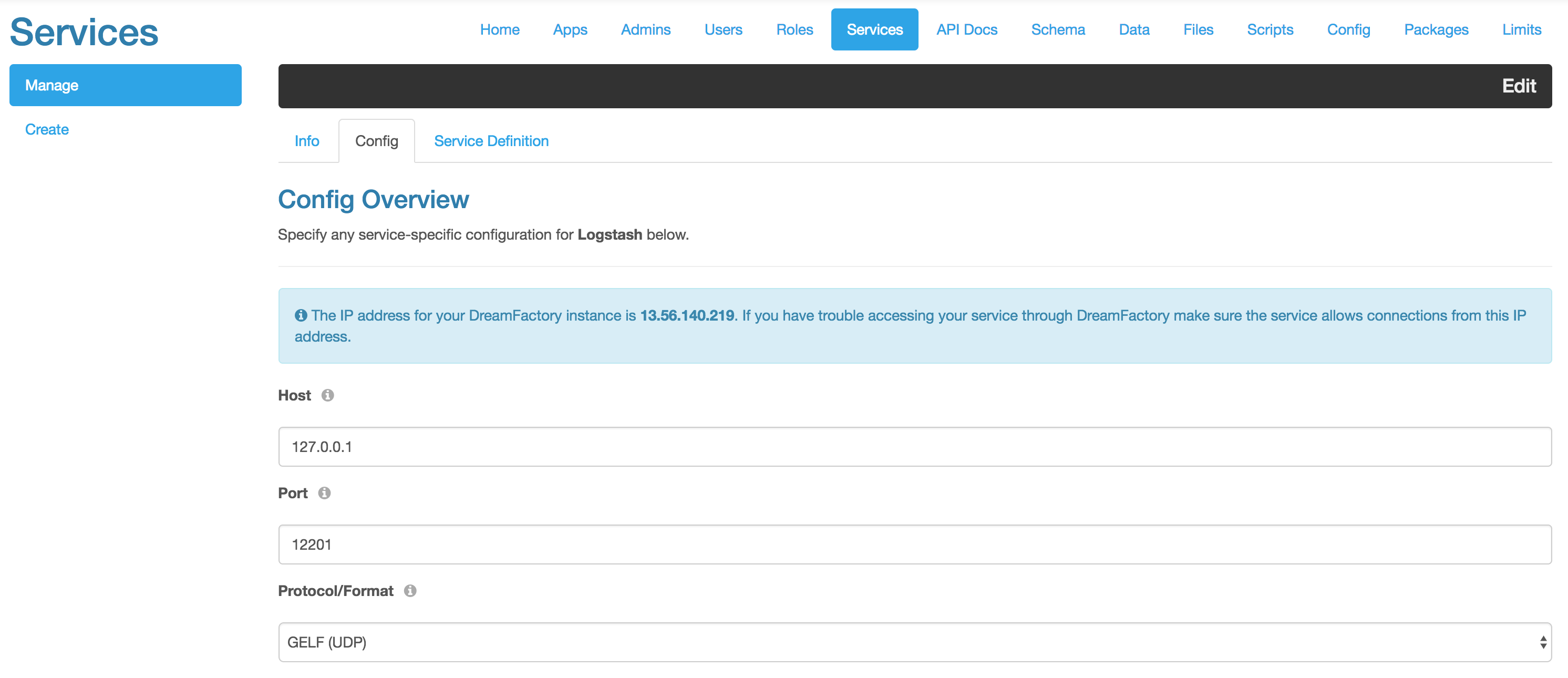
在第二个屏幕截图中,您可以通过Logstash连接器看到一些可用的日志记录选项。我还添加了一些我想要记录的服务。您可以选择要记录的各种级别的信息。要了解更详细的信息,请参见此文章.有效的选项是:
- 致命的
- 错误
- 警告
- 信息
- 调试
- 跟踪
- 信息
从弹性栈中过滤敏感数据
敏感信息,如社会保险号、出生日期和遗传数据,通常必须以特殊的方式处理,并且通常完全排除在日志文件之外。幸运的是,Logstash提供了一套功能强大的功能,可以在数据插入Elasticsearch之前删除和修改数据。例如,如果你想阻止API密钥被记录到Elasticsearch,你可以定义以下过滤器:
Filter {json {source => "message" remove_field => ["[_platform][session][api_key]", "[_event][request][headers][x-dreamfactory-api-key]"]}}故障排除您的Logstash环境
如果你在Kibana中没有看到结果,你应该做的第一件事是确定Logstash是否正在与Elasticsearch对话。在Logstash日志中可以找到有用的诊断信息LS_HOME /日志或者可能在内部/var/log/logstash.如果您的Logstash环境无法与Elasticsearch对话,您将在日志中发现如下错误消息:
[2019 - 02 - 14 t16:20:24,403][警告][logstash.outputs。试图恢复到已死亡的ES实例的连接,但得到一个错误如果Logstash无法与Elasticsearch通信,并且服务驻留在两台独立的服务器上,那么问题很可能是由于防火墙限制造成的。
额外的Logstash资源万博手机登录平台
DreamFactory API速率限制
可以为特定的用户、角色、服务或端点设置DreamFactory限制。此外,您可以为每个用户设置限制,每个用户将获得一个单独的计数器。可以创建限制以仅与特定的HTTP谓词交互,例如得到或者你可以为a创造另一个极限帖子到特定的服务。端点限制还提供了另一种强大的方法,可以在DreamFactory实例中进行粒度级别的限制。
限制层次结构
可以创建覆盖整个实例或覆盖特定端点的限制。当限制组合在一起时,将创建一种类型的限制层次结构,其中更广泛的限制有时可以覆盖更细粒度的限制。例如,为每分钟500次点击的整个实例创建的限制。如果为特定服务创建了每分钟1000次点击的限制,则实例限制将发出一个HTTP 429(超过限制)错误在一分钟内500次,所以服务限制永远不会达到1000。在创建多个限制和规划限制策略时,一定要牢记大局。将基础更广泛的限制类型设置为更细粒度的适当级别。
限制类型
每个API限制都基于限制到期和重置的特定时间段。这里的选项是可配置的,包括分钟、小时、天、7天(周)和30天(月)。各种限制类型与限制期限相结合,允许对实例进行广泛的控制。下表概述了可用的不同类型的限制。
| 限制类型 | 描述 |
|---|---|
| 实例 | 控制整个实例的速率限制,以包括所有服务、角色和用户。这里的限制计数器是累积的,与用户、服务等无关。 |
| 用户 | 为指定用户提供速率限制控制。在同时设置了用户限制和每个用户限制的情况下,特定于用户的限制将根据速率覆盖每个用户。但是,两个计数器仍然会递增。 |
| 每个用户 | 为每个用户设置速率限制。这与整个实例之间的主要区别是,每个用户都获得一个单独的计数器。 |
| 角色 | 启用指定角色限速功能。 |
| 服务 | 通过指定服务启用限速。 |
| 用户服务 | 在特定服务上为特定用户启用速率限制。 |
| 用户服务 | 为特定服务上的每个用户启用速率限制。 |
| 端点 | 通过指定端点启用速率限制。 |
| 终端按用户划分 | 在特定端点上为特定用户启用速率限制。 |
| 每个用户的端点 | 为特定端点上的每个用户启用速率限制。 |
| 限制时间 | 限制时段包括分钟、小时、天、7天(周)和30天(月)。限制期限确定限制的有效时间,直到期限到期后自动重置。 |
通过API的限制
与DreamFactory中的所有其他服务一样,只要用户对系统/资源具有适当的权限,就可以单独通过API来管理限制。可以从以下端点管理限制:
api / v2 /系统/限制-端点管理CRUD操作的限制。api / v2 /系统/ limit_cache-检查当前限制音量级别和手动重置限制计数器的端点。
创建限制
限制是通过发送帖子来/ api / v2 /系统/限制.要创建一个简单的实例限制,帖子端点的以下资源:
| 限制类型 | API " type "参数 | 额外需要的参数* |
|---|---|---|
| 实例 | 实例 | N/A |
| 用户 | instance.user | user_id |
| 每个用户 | instance.each_user | N/A |
| 服务 | instance.service | service_id |
| 按用户划分业务 | instance.user.service | user_id, service_id |
| 用户服务 | instance.each_user.service | service_id |
| 端点 | instance.service.endpoint | service_id、端点 |
| 终端按用户划分 | instance.user.service.endpoint | User_id, service_id, endpoint |
| 每个用户的端点 | instance.each_user.service.endpoint | service_id、端点 |
| 角色 | instance.role | role_id |
标准要求参数包括:类型、速率、周期、名称。下表描述了在创建限制时可以传递的所有可用参数。
| 参数 | 类型 | 要求 | 描述 |
|---|---|---|---|
| 类型 | {字符串} | 是的 | 创建的实例类型。详细说明见上表 |
| key_text | {字符串} | N/A | 仅限信息字段。该键由系统自动生成,是限制的唯一标识符。 |
| 率 | {整数} | 是的 | 在限制时间内允许命中的次数。 |
| 期 | {enum} | 是的 | 限制自动重置的时间段。有效值为:minute, hour, day, 7-day, 30-day |
| user_id | {整数} | (见上表) | 用户类型限制的用户Id。 |
| role_id | {整数} | (见上表) | 角色类型限制的角色Id。 |
| service_id | {整数} | (见上表) | 用于服务和端点类型限制的服务Id。 |
| 名字 | {字符串} | 是的 | 限制的任意名称(必需的)。 |
| 描述 | {字符串} | 没有 | 限制说明(可选) |
| is_active | {布尔} | 没有 | 默认为true。此外,您可以创建一个处于“非活动”状态的限制,稍后可以激活(可选)。 |
| create_date | {时间戳} | N/A | 信息只。 |
| last_modified_date | {时间戳} | N/A | 信息只。 |
| 端点 | {字符串} | (见上表) | 端点字符串(需要时见上表)。此外,请参考端点限制部分以获得更多信息。 |
| 动词 | {enum} | 没有 | 默认为所有动词。传递单个谓词只会为这些请求设置限制。可以用任何限制类型指定。有效值为:得到,帖子,把,补丁,删除 |
用户与每个用户限制
您可以为整个实例、特定服务或特定端点向特定用户分配限制。这种类型的限制只会影响单个用户,而不会影响整个实例、服务或端点。每个用户类型的限制也可以创建这些,主要的区别是在每个用户限制,每个用户将得到一个单独的计数器。例如,如果您对特定服务设置了限制,并将速率设置为每天1000次,那么单个用户可能会达到该限制,并且它将影响进入该服务的任何后续请求,而不管用户是谁。在每个用户服务类型的限制下,每个用户将获得一个单独的计数器,每天达到1000个。这也适用于其他限制类型。
服务限制
当您创建服务限制时,您是基于特定的服务进行限制。要创建这种类型的限制,请传入要创建的服务的id。
角色的限制
角色限制与服务限制大致相同,但是结合Role中的安全设置,您可以创建一些真正强大的基于角色的限制组合。
端点的限制
端点限制允许API管理员对哪些类型的请求可以被挑选出来进行限制。基本上,管理应用程序的API Docs选项卡中任何可用的东西都可以用作端点限制。端点限制可以,并且在某些情况下应该与特定的动词结合使用。由于DreamFactory中的所有端点都绑定到服务中,因此在创建端点限制时需要service_id。所以,如果你有目标db / _table /接触,您将需要通过id选择db服务,并以字符串形式提供端点的其余部分。例子:
只有当传入的请求的特定资源与存储的限制完全匹配时,才会创建如上示例所示的限制类型。因此,只有_table /联系会增加限制计数器吗_table /联系/ 5或者端点参数的进一步变化。
通配符端点
因为可能存在这样一种情况,即您希望限制端点以及端点上的所有变体,所以我们内置了向端点限制添加通配符的功能。通过添加一个通配符*字符到端点时,您将创建一个端点限制,该限制将与特定端点以及任何其他参数一起命中。每个端点限制都与一个服务相关联。因此,端点限制只是服务类型限制的扩展。服务限制将对服务下的每个端点提供有限的覆盖,而端点限制更有针对性。结合通配符和特定动词,端点限制变得非常强大。
限制缓存
默认情况下,限制使用基于文件的缓存存储系统。垃圾收集是自动的,并基于限制期限。您可以通过API轮询限制缓存系统,以获得每个限制的当前命中计数。的得到调用system/limit_cache将提供限制的Id、唯一键、最大尝试次数和当前尝试次数,以及限制期间的剩余尝试次数。
清除限制缓存
清除限制缓存涉及重置特定限制的计数器。此外,所有的限制计数器可以通过传递allow_delete = true参数指定system/limit_cache端点。通过Id的特定极限系统/ limit_cache端点,例如系统/ limit_cache / 11将只清除该特定限制的限制计数器。
限制缓存存储选项
默认情况下,限制缓存使用基于文件的缓存。此文件缓存与梦工厂(主)缓存是分开的,因此当梦工厂中的缓存被清除时,限制计数不受影响。Redis也可以与限制缓存一起使用。请参阅.env-dist文件限制缓存选项。